Large Language Models (LLMs) are a new and promising class of deep learning models used for a variety of tasks, including, but not limited to, text generation, classification, and translation. They are trained on large amounts of data and can be fine-tuned to perform specific tasks. In essence, for a given prompt LLMs will produce a continuation or completion that best fits the context, training data, and alignment. With a recent rise in popularity, LLMs already add value to a variety of applications, both consumer-facing (e.g. chatbots, writing assistants, tutors, and search engines) and internal (e.g. natural language interfaces for databases, code generation, enterprise search, knowledge management, and fraud detection).
Identifying the most feasible prompt for a given task often takes the shape of a creative ideation process, consisting of multiple steps for coming up with various prompts and evaluating their outputs, as well as other criteria such as token count.
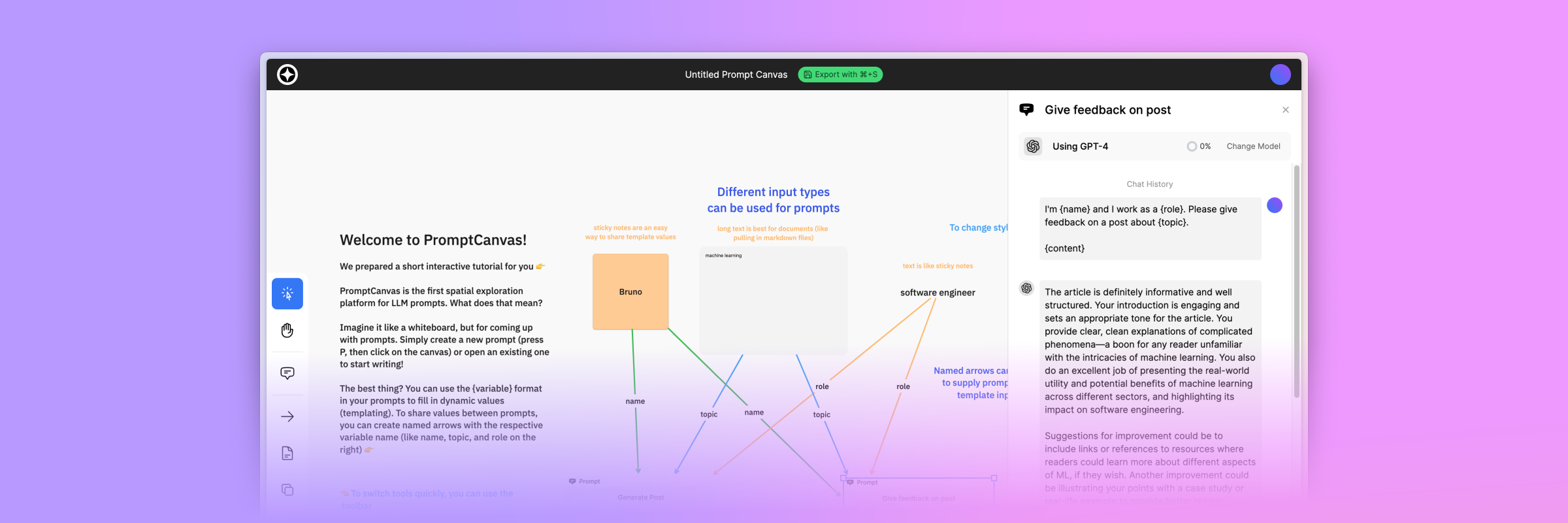
Existing interfaces for LLMs largely follow the tried-and-tested conversational paradigm, which works well for chat-based applications, but is not ideal for exploration and diverging before converging on a final prompt: Working with dynamic values and re-using content and outputs of other prompts often involves copying and pasting text and switching contexts, creating friction in the ideation process.
To this end, we present PromptCanvas, a spatial prompt interface that allows users to explore and optimize prompts visually. Starting today, you can use PromptCanvas to explore and find the best prompts, for free.
Use Cases and Proposed Solution
While prompt engineering is a new field covering the end-to-end process of ideation, optimization, and monitoring of LLM prompts, PromptCanvas is laser-focused on the ideation process. While other tools offer rich comparison and tuning options for prompts, they enforce a rigid framework with limited potential for coming up with new prompts and re-using and combining existing ones. This lack of flexibility can be a major roadblock in the ideation stage, where the goal is to diverge and come up with many different prompt candidates, before converging on a final prompt.
We tried out different approaches to interface design with creativity and flexibility in mind, converging on a canvas-based experience for creating, connecting, and comparing prompts. Canvas and whiteboard software has become a staple in the remote work environment, helping teams brainstorm, ideate, and collaborate. We wanted to bring the same experience to prompt engineering, applying already familiar concepts to a new domain.
Users should not be limited to a fixed number of prompts on their screens, and neither should every prompt look the same. Because of this, we chose to extend the whiteboard experience with the concept of prompts. This way, we could leverage existing progress in the field of canvas and whiteboard software while adding a new dimension to it.
Putting all things together, PromptCanvas helps marketing teams create copy for different platforms based on a single source of truth, writers get feedback on and improve their work, and developers craft and test prompts for their applications. Any case where knowledge should be infused into a prompt can benefit from the rich spatial templating experience built right into PromptCanvas. In the end, users can assemble an entire pipeline of prompts, tracking dependencies and re-using content and outputs of other prompts to create deliverables for any objective.
Product Development
We built PromptCanvas in a two-week cycle, starting by limiting the scope to fit the time constraints. First, we reduced risk by working on the canvas extension, getting familiar with the internal APIs and state management of the canvas framework. Next, we built the backend layer to process chat completion requests, later on adding authentication and service quotas on top. After the first week, we conducted multiple usability tests with prospective users, getting important feedback to improve the design and user experience.
From the usability tests, we prioritized the core editing experience, as well as in-product tutorials and a solid onboarding. We cut scope by limiting the available models as well as removing support for completion models, focusing on the ideation stage with chat models. These decisions were crucial to building the best possible experience in the given time frame.
In the second week, we overhauled the design and worked on important production-readiness features, such as robust error handling, monitoring, and service quotas, which are further detailed in the production readiness section.
While we initially expected to spend more time on integrating the language models, we were able to leverage previous work on making LLMs accessible to web applications. This way, we spent the most time crafting a solid user experience and simplifying the design to make it accessible to a wide range of users.
UX Design
PromptCanvas was designed for a variety of users, including marketers, writers, and developers. We wanted to create an accessible experience for users with different backgrounds, while still providing a rich feature set for power users. Having real users interact with the product without any prior knowledge was a key part of the UX design process, allowing us to identify and fix usability issues early on. In the end, there is no faster way to spot bugs and usability issues than putting a user in front of your product and observing them using it.
The biggest issues early on were that users would not naturally discover features and often misunderstood icons for different functions. This prompted us to add an in-product tutorial, as well as choose more descriptive icons and add tooltips for the available toolbar items.
Furthermore, designing the chat experience required multiple iterations leading up to the final iteration.
Optimizing PromptCanvas for a mobile experience was not a priority in the beginning, but we nonetheless wanted to make sure users could navigate the canvas and send prompts. Making the sidebar accessible was the least difficult implementation step as the canvas proved much harder to explore on mobile. While it is possible to use PromptCanvas on a mobile device, we strongly recommend using a larger screen for the best experience.
UI Design
We designed the user interface from wireframes down to high-fidelity mockups, verifying the design with the results of the usability tests at each step. The final design was never meant to be a pixel-perfect implementation requirement but rather acted as a guideline similar to a design system.
To model the different states of the application, we heavily used Figma's component and variant features, allowing us to put together mockups for each possible system state. This made sure error states were not an afterthought, but rather a core part of the design process.
Engineering
PromptCanvas is built as a Next.js application with Vercel Edge Functions as the backend layer. The canvas is built on top of TLDraw, a canvas framework with an active community. The frontend is styled with TailwindCSS and animated with Framer Motion, Radix UI provides accessible UI primitives. Persistence is handled by Neon, a serverless Postgres database, and Upstash, a serverless Redis key-value store. The application is monitored with NewRelic, and Optiboy is used for double opt-in newsletter subscription management. AWS SES is used for sending transactional (authentication) mails. We use GPT-3.5-Turbo and GPT-4 as underlying language models, both provided by OpenAI.
We chose this tech stack as a combination of proven technologies (React, PostgreSQL, Redis) with edge deployment capabilities (Vercel Edge Functions) and a vibrant community (TLDraw, TailwindCSS, Radix UI). This way, we could focus on building the product, while relying on existing solutions for common problems. The edge deployment capabilities of Vercel Edge Functions allow us to run the application on a global CDN, with a serverless backend layer. This way, we can serve the application to users around the world with low latency, while keeping costs low and scaling with demand.
Initial engineering challenges included streaming chat completion responses to the frontend, which we solved by integrating with the Vercel AI SDK. This design decision nudged us to use Vercel Edge Functions in the backend, which was a reasonable trade-off in terms of development time and cost with the potential future benefit of being able to run the entire application on the edge, including the data stores. One remaining limitation is that OpenAI is, as of the time of writing, exclusively hosted in the US, which means that users outside the US will experience higher latency when using PromptCanvas.
Another big risk we wanted to mitigate early on was getting familiar with the TLDraw canvas, understanding the internal APIs, and building our extension on top of it. We tried to remove all non-essential features from the canvas at first but decided to keep the context menu and existing shapes in our final product, merely customizing the built-in user interface.
While most engineering tasks were relatively straightforward, hardening the application for production availability required thorough planning and careful execution. We decided to devote a dedicated section to this topic, as it is often overlooked in the early stages of product development and critical for moving into production.
Production Readiness
Throughout our exploration of the prompt engineering space, we noticed that many tools are not production-ready, often lacking important security and monitoring features. Most projects are built on a weekend and shipped to the public seemingly without consideration for production-readiness that is inherent in software engineering and expected for any commercial product. This is not a criticism of the developers, but rather a symptom of the fast-paced nature of the field, where new tools are released daily. We wanted to avoid this pitfall and integrate countermeasures early on.
In addition to adding the bare minimum of KYC with email authentication, we have identified four main areas of concern: Malicious prompts, budget overruns, service outages due to high load, and insufficient observability into the system. We will discuss each of these in detail below.
Malicious Prompts
As the backend directly communicates with the OpenAI API, we need to make sure that malicious prompts violating the OpenAI usage policies are not sent to the Chat Completion endpoint. Fortunately, OpenAI provides a free Moderation endpoint to classify text as safe or unsafe. We run every submitted prompt and text content through this endpoint, immediately rejecting prompts that are classified as unsafe and suspending users that repeatedly submit unsafe prompts.
Additionally, we attach the respective account ID to all chat completion requests, allowing the OpenAI team to identify and notify us about users that violate the usage policies in any way not caught by the Moderation endpoint.
Prompts are also never shared between users, and the current system does not offer other sharing or workspace-level collaboration features.
Fixed Budget
To prevent a 'hug of death' scenario or intentional abuse of the service, we decided on a fixed budget, which is distributed to each user. To incentivize subscribing to this newsletter, newsletter subscribers receive model access to GPT-4 and extended tokens for GPT-3.5-Turbo, creating a two-tiered system.
While we could have allocated a fraction of the monetary budget to each user, we opted to partition the budget into a targeted active user range, then convert the per-user budget into GPT-3 and GPT-4 tokens based on the current prices. This way, quotas are bound to token usage. Alternatively, we could have allocated a monetary budget to each user, allowing for higher flexibility in usage. We may explore this option in the future if the current system proves to be too restrictive. For the time being, we can adjust the target budget and quotas on the fly, allowing us to scale with demand.
The token budget is encoded in service quotas, which the client displays as progress gauges in the model switcher and next to the send button. This way, users can see how many tokens they have left at any given time. For each incoming chat completion request, we calculate the expected token usage by tokenizing the input and adding the maximum output tokens for the selected model. If the request exceeds the token budget, it is rejected and the error is displayed in the UI. Recent daily and all-time token usage is recorded in the key-value store.
To prevent any issues in our budgeting calculation from affecting the service, we have configured hard and soft budget limits in the OpenAI billing settings as well, creating a second layer of protection.
Rate Limiting
While service quotas enforce daily and all-time usage limits, we need to add further guardrails to prevent users from sending an excessive amount of requests in a short period. We configured an hourly request threshold for each user, which is enforced by the backend layer. If a user exceeds the threshold, they are temporarily blocked from sending further requests. The current usage is tracked in Redis and resets every hour.
Observability
The ability to understand what is happening in a production system is extremely important for any software deployment. While we ensured users were limited in their ability to abuse the service, there are still many possible ways for the system to fail, including unexpected connection issues with the data stores, availability issues with external APIs, and anomalies in user activity. For this reason, we have instrumented the application with error tracking, event reporting, and request logging. We do not collect or store any prompts or chat messages in our observability stack, nor do we store these in the data stores.
Preparing a production-ready UI
To support all the measures implemented in the backend, we extended our UI with error handling, awareness of service quotas and rate limits, and subscription management features.
There are some inherent limitations in opening PromptCanvas up to different models, as we now require tokenizers for measuring model usage, as well as a classifier for malicious input. This is part of the reason why we decided to limit the available models to GPT-3.5-Turbo and GPT-4 for the initial release.
Future Work
We initially planned PromptCanvas to support collaboration and teamwork features such as workspaces, sharing, commenting, and real-time collaboration. Due to our restricted cycle duration, we had to cut the scope and focus on the core editing experience. If the demand for these features is high enough, we will explore adding them in future iterations.
The same goes for supporting additional LLMs such as LLaMA, Cohere's Command model, Anthropic's Claude, and others. We are excited to see how the field evolves and with it the demand for different models.
Try it out
PromptCanvas is available for free, starting today. You can sign in with your email address. As a subscriber, you will receive free GPT-4 tokens, as well as a higher rate limit. We can't wait to see what you build with it!

Thank you for reading the first issue of Gradients & Grit. If you enjoyed this issue, please consider subscribing to the newsletter to be the first to know about new issues and other updates. If you have any open questions, suggestions, or feedback in general, please join the Discord community!
In the coming weeks, we will dive deeper into integrating LLMs into your applications, best practices for making your AI-enabled software production-ready, and more. Stay tuned!
PromptCanvas would not have been possible without the help of the following people: Hendrik Wagner, Jonas Faber, Benjamin Buhl, and Timo Köthe.